

Assist. Prof. Dr Ashwan A. Abdulmunem
Computer Science Department
Introduction
Computational imaging (CI): is a step-by-step procedure for producing images indirect means from data utilizing algorithms that require a substantial amount of computing [1].In a nutshell, it refers to digital picture capture and processing methods that combine computing with optical encoding. In comparison to earlier imaging, computational imaging systems require close incorporation of the sensor equipment and the computing to produce the desired pictures. Because of the widespread accessibility of powerful computer technologies (such as GPUs and multi-core CPUs), developments in techniques, and current sensing gear, imaging systems now have greatly expanded capabilities. Computational imaging systems are used for a wide variety of applications such as microscopy, tomographic imaging, MRI, ultrasonic imaging, computational photography, Synthetic Aperture Radar (SAR), seismic imaging, and so on. The combination of sensing and computing in systems for computational imaging enable access to information that would otherwise be unavailable.
The following figure explains computational imaging:
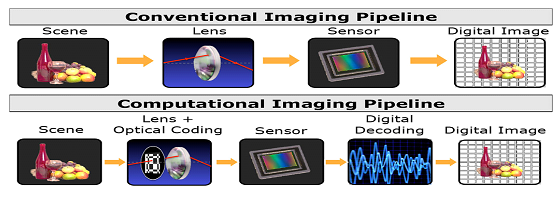
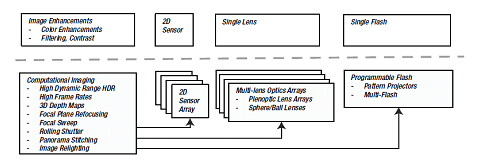
Computational imaging technologies are compared to traditional cameras. In the figure below (upper row), a basic camera prototype with a flash, lens, and imaging equipment is followed by picture upgrades such as refining and color correction (lower row) CI using configurable flash, optical arrays, and sensor matrices, followed by CI implementations[3].
Techniques
⦁ 2D Computational Imaging
As computational cameras, novel architectures of configurable two-dimensional sensor arrays, lenses, and illuminators are produced [4]. The implementations involve different applications ranging from digital photos to industrial and military uses. Using CI techniques to improve images is an example input for various computer vision systems.
⦁ 3D Computational Imaging
Because computer vision has traditionally been engaged with obtaining 3D information from 2D pictures, which has resulted in a wide variety of issues about accuracy and invariance, using a 3D depth measurements for computer vision gives an underestimated benefit for many vision applications. When struggling found to achieve good digital images using conventional lighting and lens, CI can often provide them. The CI applications require a good contrast, good color, more depth of field, 3D surface data, or many other targeted image figures. The CI offers techniques to get images that are optimized for vision applications. The outcome of many CI resources are images that are already segmented or have the features related to a specific task highlighted or extracted. Machine vision systems’ increased intelligence and performance, as well as new market sectors, are pushing advancements in image and lighting technology. When enhanced throughput is required for high-speed operations, very high-intensity LED illumination for both continuous line scan, and pulsed applications have been created.
Types of Computational Imaging Cameras
Array Cameras
An array camera consists of numerous cameras organized in the shape of a two-dimensional matrix, such as a 4×4 matrix, to give a variety of computational imaging options. Commercial cameras for mobiles are starting to become available. They could compute disparity using the multi-view stereo approach, which uses a mixture of sensors in the array, as previously mentioned. An array camera has a wide baseline image set to calculate a 3D depth map that can notice through and around geometric distortion, high-resolution images interpolated from the low-resolution images of each sensor, all focused images, and specialized image refocusing at one or more positions. The maximum value of the aperture of an array camera is equal to the largest distance among the lenses.
Radial Cameras
A radial camera, which combines 2D and 3D imaging, is made up of an angular or radial reflector around the lens and a two-dimensional image sensor. The radial reflector, as illustrated below figure, permits a 2D picture to develop in the sensor’s center while a radial toroidal image including reflected 3D information forms around the periphery. The depth of the picture is the toroidal information may be reconstructed by reprocessing it into a feature virtualized environment on the geometry of the conical mirror, and the two-dimensional information in the image’s center can be layered as a texture map for complete three-dimensional reconstruction.

Plenoptics
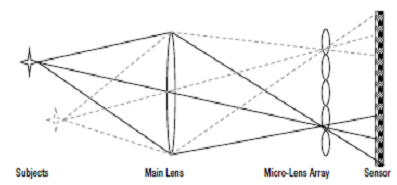
Multiple optics generate a three-dimensional space described as a light sphere using plenoptic techniques. Plenoptic systems photograph a four-dimensional light field and select pictures from the source of light after post-processing using a collection of micro-optics and original optics. Plenoptic cameras, as shown in the following figure, only require a single image sensor. The four-dimensional light field can be presented as a volume dataset, each point being interpreted as a voxel, or as a 3D vertex with a 3D oriented area, color as well as transparency and color, or as a three dimensional pixel with a three-dimensional aligned surface, color, and occlusion. The following figure explains this type of camera.
References
[1] M. Levoy, “Light Fields and Computational Imaging,” in Computer, vol. 39, no. 8, pp. 46-55, Aug. 2006, doi: 10.1109/MC.2006.270.
[2] https://www.spie.org/news/5106-analyzing-computational-imaging-systems?SSO=1
[3] Scott Krig,” Computer Vision Metrics”,2014.
[4] Ragan-Kelley, Jonathan, et al. “Decoupling Algorithms from Schedules for Easy Optimization of Image Processing Pipelines.” ACM Transactions on Graphics Vol. 31(4) (2012).


























































